第二节课讲的是C和gdb,这些比较简单,我主要关注实验部分。详细的实验要求见lab: system calls,实验前需要阅读xv6 book的一些章节和源码,为了保证连贯性,我阅读了2-4章。
xv6 gdb调试
如果大家足够有耐心的话,可以选择使用gdb调试,去一步一步debug内核的执行过程。这里介绍下xv6的调试方法。首先在xv6-labs-2020目录下:
make qemu-gdb应该会出现
然后打开另一个终端,进入riscv-gnu-toolchain的编译产物所在目录的bin目录,我这边之前设置的是/usr/local/opt/risc-gnu-toolchain/bin,编译工具详情参考6.S081(一)。然后执行以下过程:
# 启动gdb
riscv64-unknown-elf-gdb
# 接着在gdb中输入以下命令
# 1. 切换到xv6-labs-2020所在目录
cd /home/xxx/xv6/xv6-labs-2020/
# 2. 加载内核执行文件
file kernel/kernel
# 3. 打断点
b _entry
# 4. 连接qemu-gdb server
target remote 127.0.0.1:26000
# 5. 使用gdb命令开始调试
c; si; ni; x/5i $pc; i register a0可以看到下图所示的结果:
物理资源的抽象
抽象思想是非常重要的,包括设计模式中的依赖倒置原则也强烈建议高层模块和底层模块都应该依赖于抽象。操作系统无疑是在抽象这一块做的最好的产品之一,它把物理资源(如CPU、内存、硬盘等)抽象成一系列模型(如文件、进程等),然后应用程序只需要按照这个模型进行编程即可。
举个例子,我们在餐馆吃饭的时候,只需要点菜,付钱,吃,然后走人就可以了。对于我们来说,只需要完成这些步骤就行了,而不需要考虑这些之外的东西。而实际上餐馆需要早上买菜,洗菜,然后烧成菜品,在顾客吃完后,还需要收拾饭后垃圾,实际上餐厅给我们提供了一个方便且快捷的用餐环境(抽象)。当然我们也可以选择不去餐厅吃,而是自己买菜自己烧,然后收拾厨余和饭后垃圾,但显然过程会相较于餐厅用餐更加繁琐且麻烦。
操作系统就像是一个餐厅,给每一个用餐的客人(应用程序)提供美食(物理资源抽象)。操作系统承诺每个应用程序都能以进程形式运行,进程能读写文件,甚至能跟其他应用程序进行沟通等。基于这个抽象模型,开发者调用系统调用开发应用程序。而在开发者处理逻辑之外的地方,操作系统默默完成进程调度和隔离、文件操作抽象到具体硬盘操作等等的工作,为应用程序保驾护航。当然应用程序也可以自己买菜,自己使用CPU资源和读写硬盘,但是这也意味着实现一个小功能都要考虑一系列过程,对开发者的水平也是一个很大的挑战。
接着我们再深入一点,这个进程抽象到底包含哪些内容呢?简单来讲,就是这个进程抽象仿佛拥有整台计算机的CPU、内存等。操作系统为了让用户进程有这种假象,就要对CPU、内存等进行一些虚拟化操作,使进程活在自己的世界里。
- CPU:操作系统通过进程调度(如时间片轮转等),通过保留当前进程的状态,然后切换到新线程执行,然后再切换。使得每个进程感觉自己一直都在运行,但是事实上,如果有A、B、C三个进程,可能实际CPU在1秒的运行过程是:300ms运行A,300ms运行B,300ms运行C(另外的100ms是2次进程切换消耗的时间)。
- 内存:使用进程页表来虚拟化内存,用虚拟的页表号(虚拟内存)来对应真实的页框(物理内存)。
进程
进程是程序运行时的动态描述,在xv6中使用proc结构体(kernel/proc.h)进行表示。
1 | struct proc { |
其中5-10行的变量主要是描述进程的执行状况的,13行以后的变量这里简单介绍一下:
- kstack:进程的内核栈,每个进程都有用户栈和内核栈。当进程运行用户指令时,只有其用户栈被使用,其内核栈则是空的。然而当进程(通过系统调用或中断)进入内核时,内核代码就在进程的内核栈中执行;进程处于内核中时,其用户栈仍然保存着数据,只是暂时处于不活跃状态。
- pagetable:进程页表,是内存管理的重要内容。
- trapframe:用于描述系统调用时的状态,指导内核执行相应的动作。
- context:执行上下文,主要是一组寄存器的保存与切换。
- ofile:进程的打开文件表,能够直接映射文件的inode,但实际上内核通过全局的ftable来管理所有打开的文件。
- cwd:工作目录
有些内容暂时不是很清楚,但是后文会慢慢讲清楚。
CPU权限
对于系统调用,我们知道用户代码不能直接执行,要转交给内核代码执行。很自然的,就可以想到内核相较于用户具有更高的权限。那么这种权限是怎么实现的呢?其实是由CPU的硬件支持的。在RSIC-V中,CPU有三种模式:
- 机器模式:该模式下能执行所有的特权操作,主要是用于开机时配置计算机。CPU最开始就是在这个模式下启动的。
- 监管模式:该模式能够执行一些特权指令,比如打开或关闭中断,读写页表寄存器。
- 用户模式:只能执行一些普通指令。
其实CPU的特权划分很常见,比如x86也有4个特权级(0最高,3最低)。大多数操作系统使用x86的特权级0和3,分别用于内核模式和用户模式。
这里也可以把监管模式又称为内核态,用户模式称为用户态。顾名思义,用户进程大多数情况下运行在用户态,当其调用系统调用时,则会切换到内核态,由内核去判断输入参数的合法性,并决定是否真正执行系统调用。通过这一机制,就可以实现内核与用户程序的关系(类似于root用户和普通用户)。
xv6启动
在介绍xv6启动前,我想先介绍一下计算机是如何启动的(不涉及操作系统):
- 第一阶段(BIOS):开机程序被刷入ROM芯片,计算机通电后第一件事就是读取ROM芯片中的程序。
- 硬件自检:BIOS程序首先检查硬件是否满足运行的基本条件。如果没有问题,则会显示CPU、内存等信息。
- 转交控制权:硬件自检没问题,BIOS需要把控制权转交给下一阶段的启动程序。这个启动程序是由BIOS选项中的“启动顺序”决定的(如从U盘启动、从硬盘启动等)。
- 第二阶段(主引导记录):BIOS按照“启动顺序”选取启动设备的第一个扇区,这个扇区也就是“主引导记录”。主引导记录中包括了机器码,分区表和主引导记录签名。其中主引导记录签名则表明该设备是否可用于启动;分区表则表明了硬盘的各个分区(1个硬盘可分为多个分区,类似于windows的C盘、D盘等)。机器码根据分区表记录,选择启动分区。
- 第三阶段(硬盘启动):此时计算机的控制权转交给了硬盘的某个分区。此时又分为三种情况:
- 卷引导记录:卷引导记录告诉计算机操作系统在这个分区里的位置,然后加载操作系统。
- 扩展分区和逻辑分区:分区可能是扩展分区,那么需要通过其分区表,一层一层寻找到启动的逻辑分区。
- 启动管理器:计算机在读取主引导记录的机器码后,不将控制权交给某个具体分区,而是运行“启动管理器”(如Linux的Grub)。由用户选择启动哪个操作系统。
- 第四阶段(操作系统):操作系统的内核首先被载入内存,然后开始进行操作系统阶段的初始化。
详细的启动过程可见计算机是如何启动的。xv6 book中的启动过程是从第四阶段开始的,起始位置是由kernel/kernel.ld决定的,也就是kernel/entry.S中的_entry,这也是操作系统启动的开始。
1 | _entry: |
其实是给每个CPU分配4K的栈空间,然后让sp指向栈空间栈顶。相应的汇编指令可见RISC-V手册,其中stack0是一个起始地址(定义在kernel/start.c中)。
1 | __attribute__ ((aligned (16))) char stack0[4096 * NCPU]; |
当分配完毕后,调用start函数。
1 | void start() { |
需要注意的是每个CPU都会执行start,也就是最后都会跳到main函数。但是从下面的main函数看到,只有CPU0才会承担起系统初始化的工作。
1 | void main() { |
这里再具体介绍一下部分方法:
- kinit:使用kmem来管理物理内存,这里的内存是从end(kernel.ld中定义)一直到PHYSTOP(end+128M),也就是只使用128M的内存。kinit中会先对这些内存以4KB为1页进行初始化(赋1)。
- kvminit:会分配一页用于内核页表,并设置页表项,其中大部分是直接映射(虚拟地址=物理地址),除了trampoline。
- kvinithart:设置satp寄存器(Supervisor Address Translationand Protection,监管者地址转换和保护)为Sv39模式,即使用低39位作为虚拟地址。然后清空快表(TLB)表项。
- procinit:初始化64个进程描述结构体,并使每个进程的kstack与实际物理内存进行映射(注意中间隔着guard page),如下图所示。
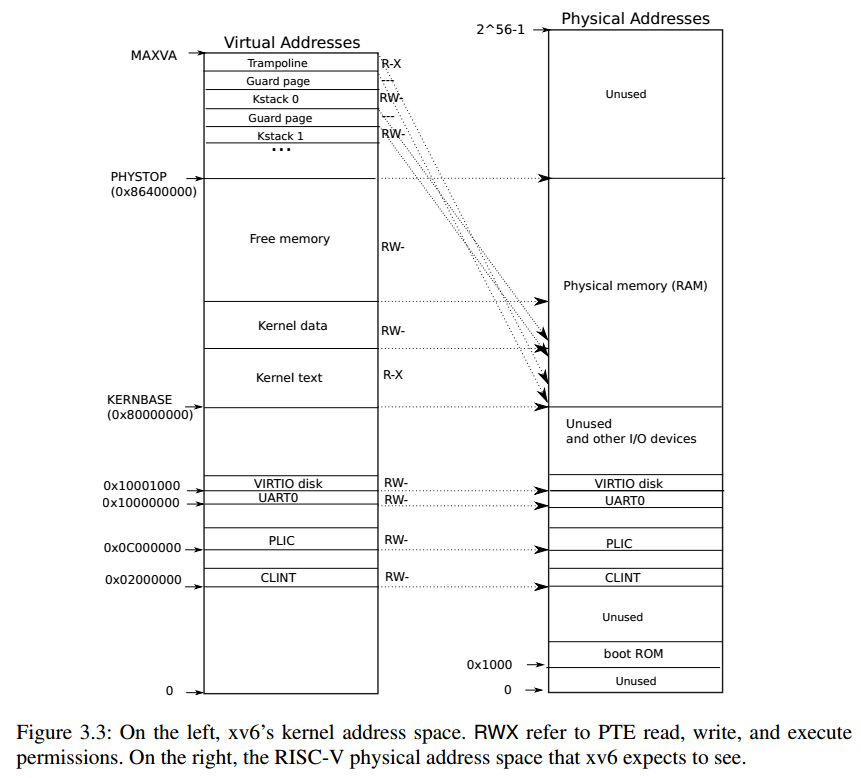
剩下的方法就不展开讲了,可以看具体的代码实现。我们接着关注第一个进程的创建,即userinit(),其代码是:
1 | void userinit(void) { |
分配进程:首先64个proc结构体已完成初始化(相应的内核栈也已创建),所以创建用户进程时,先选一个没有使用的proc,然后对该proc做以下操作。
- 分配pid。
- 分配trapframe
- 创建进程页表,其中TRAMPOLINE映射的物理内存地址和kernel页表一样。
- 初始化proc.context
这里简单说一下TRAMPOLINE和trapframe,内核页表和进程页表都有对TRAMPOLINE的映射,其物理地址是trampoline。当进程调用系统调用时,此时先不切换进程页表到内核页面,而是通过trampoline的uservec把寄存器的值存入该进程的trapframe,然后再切换到内核页表,由内核根据trapframe进行系统调用的执行。
放置执行代码:往进程页表中放入init的数据和指令,然后执行kernel/initcode.S的start,即重回内核,开始执行exec(“/init”)。代码位于user/init.c。
1 | int main(void) { |
到这里,xv6的启动也就结束了,剩下的就是sh在发挥作用了。
页表实现
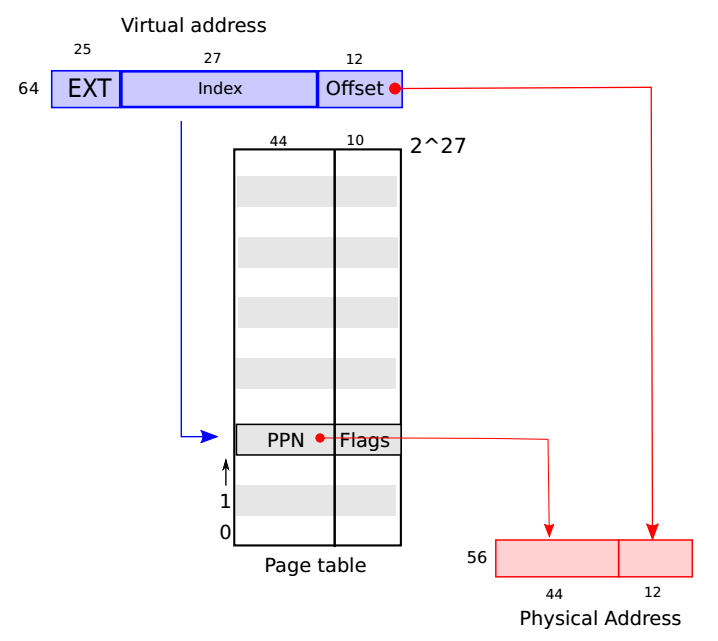
xv6页表中的虚拟内存地址仅使用64位中的低39位,页表从逻辑上可看成由页表项(Page Table Entry,PTE)组成的一维数组。每个页表大概包含$2^{27}$条页表项。每条PTE包含44位宽的物理页号(Physical Page Number, PPN)和一些标志位。通过页表中的页表项找到对应的物理内存地址如上图所示。下图显示了多级页表查询过程和页表项的flags。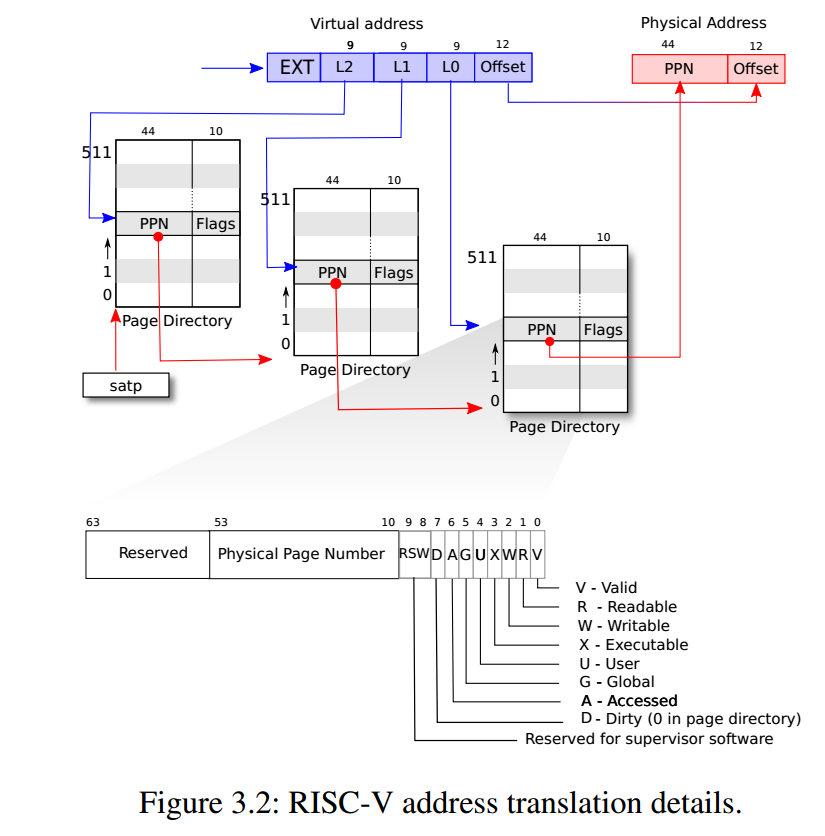
使用多级页表的好处是,能够减少驻存在内存中的页表个数,节约内存。对于分页机制,网络上有很多资料介绍,这里不多描述。
在虚拟内存中有个很重要的东西叫Translation Look-aside Buffer(TLB)。TLB会缓存PTE,从而加速查找。当xv6更换页表时(如进程切换等),CPU会使TLB的缓存失。
当用户进程申请内存时,xv6会使用kalloc分配物理内存,并给进程添加一条PTE来指向这块物理内存。
缺页
当CPU无法把虚拟地址转化为物理地址,就会产生缺页异常。缺页异常又可分为三种:
- 加载页面错误:加载操作无法通过虚拟地址得到物理地址
- 存储页面错误:存储操作无法找到对应的虚拟地址
- 指令页面错误:指令地址无法被翻译
scause寄存器表明了缺页类型。
Trap
有三种事件会使CPU搁置正在执行的指令并将控制权转移到特殊的代码进行处理。这三类事件包括:
- 系统调用:当进程执行ecall指令时,会请求内核执行。
- 异常:当指令是非法的(可能是用户代码,也有可能是内核代码),将会跳转到异常处理上。
- 设备中断:设备告知CPU其事件的完成,比如硬盘完成了读写请求。
这些事件可统称为trap(陷入)。实际上当trap发生时,需要保存此刻进程的状态以便后续继续执行。xv6中与trap相关的寄存器有以下几个:
- stvec:内核会把trap处理器的地址写在这,RSIC-V会跳转到相应地址去处理一个trap。
- sepc:当trap发生时,RISC-V会把进程的下一条指令地址写在这(不写在pc寄存器是因为pc会拷贝stvec的内容,从而处理trap)。sret指令会在trap处理完成后,将sepc拷贝到pc,从而继续运行进程。
- scause:该寄存器存储的数字表明trap发生的原因。
- sscratch:内核会在这里面放上一个值,用户trap处理的开始阶段。
- sstatus:其中两个位比较重要,SIE位表明设备中断是否被启用,SPP位表明trap发生于什么模式下。
CPU处理trap(非时钟中断)的过程如下:
- 如果trap是设备中断,根据sstatus的SIE位决定后续动作。如果SIE被清空,那么trap处理结束;如果SIE非空,则继续向下处理。
- 清空SIE位(中断处理过程不产生新的中断)
- 把pc值(下一条指令地址)拷贝至sepc。
- 保存当前模式至sstatus的SPP位上。
- 设置scause来表示trap原因。
- 设置当前模式为监管模式。
- 把stvec值拷贝至pc。
- 执行trap处理器。
可以看到硬件并没有完成切换到内核页表、切换到内核栈、保存当前其他寄存器值的工作,这些都需要内核软件来进行完成。当然这么设计也是有好处的,因为有些操作系统是没有页表机制,所以硬件承担最小的职责有助于灵活性和高效性。
xv6中与trap相关的代码位于kernel/trampline.S和kernel/trap.c中。其中trampline.S中的uservec负责将trap时的寄存器内容保存到trapframe,userret则是将trapframe的内容重新恢复至寄存器。trap.c中的usertrap则会处理具体的trap,然后usertrapret则会处理trap返回的相关事项。执行过程为:uservec -> usertrap -> usertrapret -> userret。这里简单讲下uservec:
1 | uservec: |
其实思路比较简单,就是把当前寄存器的值存到trapframe中,然后切换内核栈和内核页表,然后执行usertrap。其他三个其实也不难,大家可以自行阅读。另外需要注意的是,如果在内核空间发生trap(如设备中断和异常),那么就调用kernelvec->kerneltrap。
trace系统调用
trace系统调用其实就是给进程添加trace mask,当进程调用系统调用时会判断系统调用号是否与掩码匹配,若匹配,打印记录结果;若不匹配,则不打印。
首先我们先从user/trace.c开始,这个文件是已经写好的,关键代码如下:
1 | if (trace(atoi(argv[1])) < 0) { // 为当前进程赋予trace掩码 |
为了使用trace(),需要在kernel/syscall.h添加SYS_trace,即#define SYS_trace 22,然后在user/usys.pl中添加entry("trace");,最后在user/user.h添加trace调用,即int trace(int);,这样的话用户空间的代码就已经完成了。
接着扩展内核代码,在kernel/syscall.c中扩充syscalls,添加[SYS_trace] sys_trace,,然后在kernel/proc.h中扩充proc结构。
1 | struct proc { |
需要注意的是tmask在fork时也需要被子进程继承,所以修改proc.c的fork()。
1 | ... |
在proc.c中添加sys_trace函数:
1 | uint64 sys_trace(void) { |
最后在kernel/syscall.c中声明extern uint64 sys_trace(void);,并修改syscall函数:
1 | void syscall(void) { |
这里用syscalls_name数组来存储所有系统调用的名称:
1 | static char *syscalls_name[] = { |
至此所有工作完成。
sysinfo系统调用
跟trace类似,需要在user/usys.pl,user/user.h添加sysinfo系统调用,然后在Makefile中添加$U/_sysinfotest。然后在kernel/syscall.c中添加sysinfo的相关信息(syscalls和syscalls_name)。sysinfo的代码如下:
1 | uint64 sys_sysinfo(void) { |
其中freememsize计算剩余内存,procsize计算当前进程个数。
1 | int freememsize(void) { |
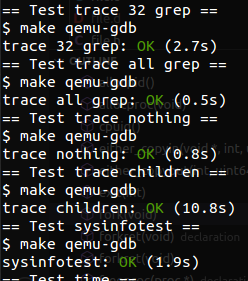
注意,需要在defs.h中声明这两个函数。至此所有工作都完成了,以下是测试的结果: