MIT 6.S081是麻省理工开设的一门关于操作系统的课程。
自2019年开始,原先的操作系统课6.828分成两门单独的课程:6.S081和6.828。前者面向本科生,侧重对操作系统的介绍;后者面向研究生,注重对操作系统的研究。
操作系统是每个计算机从业人员的基础课之一,而使用MIT的精品课程来打基础往往是最好的选择。我个人由于有一定的基础,所以学习方式是阅读讲义 + Book + Lab的方式进行学习的。如果有刚入门的朋友,可以结合每一课的video进行学习。我会选取每一课中的重点(源于Preparation、Lab或其他)和我感兴趣的地方进行记录。
第一课主要讲的是操作系统的接口。建议按照课程安排,好好预读xv6 book的第一章节。我的直观感受是写得相当好,娓娓道来,把xv6的操作系统接口通过几个方面介绍得清清楚楚。
fork、wait和exec
fork、wait和exec这几个是与进程最相关的系统调用了。fork主要用来创建子进程;exec用来执行新的程序;wait是由父进程调用,来收集已结束子进程的状态信息。
如果未及时使用wait收集子进程状态,那么就会形成所谓的“僵尸进程”,其可能会使得进程号被占用,进程号资源紧缺,最后可能会无法创建新进程。那么假设在子进程执行过程中,父进程提前结束了,此时子进程结束,由谁来收集它的进程状态呢?其实在Unix/Linux中,这种情况下的子进程称为“孤儿进程”,将由init进程收养并完成收集状态的工作。
对于fork和exec的使用,一般都是fork得到子进程,再马上调用exec执行目标程序。这种使用方式也催生了写时复制(Copy-On-Write, COW)技术,对于fork而言,创建的子进程和父进程虽然有不同的虚拟空间,但实际共用相同的物理空间,当其中的进程需要写入时,才会进行真正的拷贝,即把物理空间拷贝一份给该进程。
COW真的对fork+exec的组合有帮助么?其实不然,满足的条件比较苛刻,也就是在子进程写入前,父进程未采取任何写入行为。想象一下,如果父进程先写,那么给子进程复制一份物理空间,然后子进程调用exec,又创建新的物理空间,此时内核总共执行了3次创建过程(包括调用fork前父进程物理空间的创建),违背了COW的初衷。那么是不是子进程优先执行呢?其实也不然,这里有篇文章说得比较细:fork()父子进程运行先后顺序。
I/O和文件重定向
首先Unix对于文件描述符的设计思想很值得学习:把文件,管道和设备抽象成文件描述符,这样做的好处在于底层实现对上层透明,用户程序只需要调用一套通用的API(如read、write等),就可以对它们进行操作。这种设计思想也经常体现在一些平台类项目中:底层做的事越多,提供的抽象越简单,上层应用的开发才会更加方便。
进程在创建时,总会默认打开3个文件描述符:0(标准输入)、1(标准输出)、2(标准错误输出)。并且新分配的文件描述符总会是当前进程文件描述符表中最小的未使用描述符。基于此,使用close和dup,能够实现重定向输入输出。
1 | char *argv[2]; |
既然提到文件描述符,那么就提一下文件描述符和实际文件的关系:
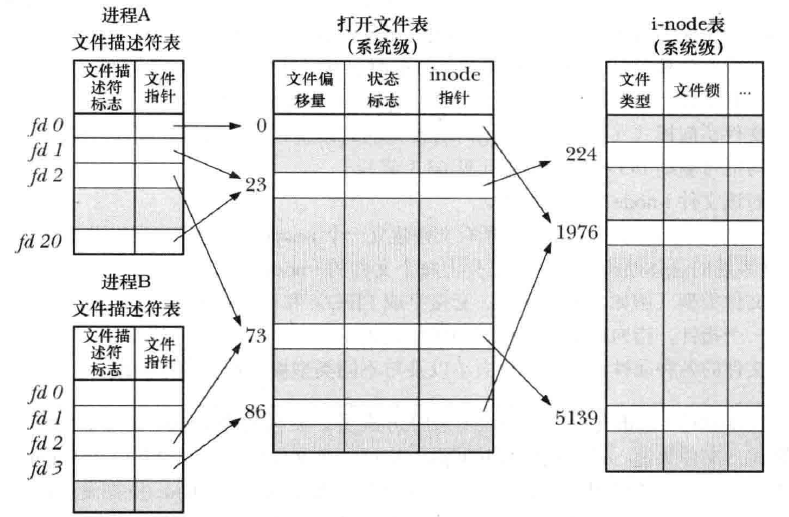
上图就已经非常直观了(图片源于文件描述符与打开文件的关系,原始出处不详)。每个进程都有一张文件描述符表(存在进程描述符PCB中),同时内核会有一张全局的打开文件表和i-node表。这三张表的作用如下:
- 文件描述符表:每一项都记录了单个文件描述符的相关信息,包括控制文件描述符操作的一组标记(如close-on-exec就是当进程执行exec时,关闭该文件描述符)和打开文件句柄的引用。
- 打开文件表:每一项是一个打开文件句柄,其中存储了该打开文件的相关信息(当前文件偏移、文件访问模式、与信号驱动相关、对i-node对象的引用)
- i-node表:每一项都是i-node对象,包括文件类型和访问权限,指向该文件持有锁的列表的指针和文件的各种属性。
这三个表通过映射关系进行连接,比如不同的文件描述表项可以指向同一个打开文件表项(无论是在同一个进程内,还是不同进程内),不同的打开文件表项可以指向同一个i-node表项。很大程度上,读写文件直接相关的是打开文件表(因为记载着偏移)。这里就有个问题,为什么不在文件描述符表中直接存打开文件表项的信息,何必再去另建一个表呢?这是因为PCB存在进程的内核栈中,而内核栈很小,当打开很多文件时,不一定够用。
pipe和临时文件
pipe管道是一种重要的进程间通信机制,严格上讲,xv6中介绍的是匿名管道,在Unix/Linux中也存在命名管道,用于非父子进程间的通信。pipe实际上一块内核缓冲区,有读端和写端。通过pipe,能很方便地实现父子进程间的通信。
1 | int p[2]; |
关于文件系统,这里提到了链接,这部分讲的链接类似于Linux中的硬链接,即多个链接指向一个i-node。
如果有兴趣的朋友也可以了解下软链接,其主要特征是具有自己的i-node,但是其中的内容指向另一个文件。
这部分的内容也提到了临时文件的创建删除用法,即open之后使用unlink断开链接。当一个i-node无链接时,也就会被删除。
xv6安装和运行
首先要配置好环境,包括RISC-V工具链、QEMU模拟器和xv6源码。官方的安装教程见Tools Used in 6.S081,但实际上会有一些问题。
我个人是在VMware中创建了一个Ubuntu虚拟机,版本号是Ubuntu 14.04.6 LTS,其内核版本为4.4.0-142-generic。
RISC-V工具链的编译
riscv-gnu-toolchain 是一个用来支持 RISC-V 为后端的C和C++交叉编译工具链, 包含通用的ELF/Newlib和更复杂的Linux-ELF/glibc两种工具链。
首先使用百度网盘进行下载百度网盘-提取码ui4j(源自MIT6.828准备 — risc-v和xv6环境搭建)。我是将riscv-gnu-toolchain的编译产物放在/usr/local/opt/riscv-gnu-toolchain下的。首先是安装必要的包:
sudo apt-get install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev libgmp-dev gawk build-essential bison flex texinfo gperf libtool patchutils bc zlib1g-dev libexpat-dev然后配置编译:
# 1. 配置
./configure --prefix=/usr/local/opt/riscv-gnu-toolchain
# 2. 编译
sudo make
# 3. 配置环境变量
vim ~/.profile
# 添加路径
export RISCV_HOME=/usr/local/opt/riscv-gnu-toolchain/bin
export PATH=${PATH}:${RISCV_HOME}
# 4. 验证
riscv64-unknown-elf-gcc -v整个编译时间会比较长,建议做会其他的事。
QEMU模拟器
这里使用官方文档的安装方式会有些问题,这里下载4.1.0版本进行安装。
# 1. 下载
wget https://download.qemu.org/qemu-4.1.0.tar.xz
# 2. 解压
tar xf qemu-4.1.0.tar.xz
# 3. 安装依赖包
sudo apt-get install libglib2.0-dev libpixman-1-dev
# 4. 配置
./configure --disable-kvm --disable-werror --prefix=/usr/local/opt/riscv-gnu-toolchain --target-list="riscv64-softmmu"
# 5. 编译安装
make
sudo make installxv6源码
注意有很多xv6的源码,这里使用课程提供的源码
# 1. 克隆源码
git clone git://g.csail.mit.edu/xv6-labs-2020
# 2. 切换分支
git checkout util
# 3. 测试
make qemush.c
这里建议对sh.c的源码进行阅读,可以加深对shell实现的思考。主体部分如下:
1 | while((fd = open("console", O_RDWR)) >= 0){ |
大致过程就是先打开三个默认的fd,然后获取键入的命令行,如果是cd就直接更改工作目录;如果不是,则fork后由子进程执行对应的命令,另外parsecmd()也是关键。parsecmd能够识别以下几类命令:
1 |
实际上parsecmd对整个命令行解析成各种cmd的树状结构,可参见下图的例子。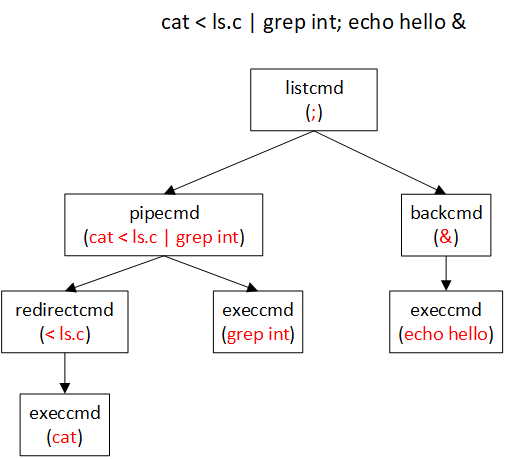
另外对于这棵cmd树的执行见runcmd。
1 | switch(cmd->type){ |
如果还想对xv6的sh.c进行更深入的阅读,可以参考xv6 shell实现源代码分析。
Lab: Xv6 and Unix utilities
Lab: Xv6 and Unix utilities分成几个部分,从易到难,很适合新手实践。本次实验的所有代码都在my lab1中。在介绍部分代码前,我更感兴趣的是用户空间的C函数调用到内核空间函数的过程。这里以sleep.c作为例子。
首先sleep.c调用user/user.h中定义的sleep函数。但是可以看到在user下的c文件中,并没有对sleep函数的实现,原因在于xv6采用的是汇编和C混合编程,相应的实现见usys.S(实际上是由usys.pl生成),这里我截取了一小部分。
#include "kernel/syscall.h"
...
.global sleep
sleep:
li a7, SYS_sleep
ecall
ret开头包含的kernel/syscall.h文件中定义各个系统调用号。然后.global sleep使得sleep对链接器可见,从而和user/user.h中的sleep函数链接起来。后续的汇编代码的意思是,首先在a7寄存器中放置系统调用号,然后ecall通过软中断(陷入)来引发内核执行系统调用。
如果对RISC-V汇编感兴趣的同学,可以阅读RISC-V手册。
然后可以在kernel/syscall.c看到syscalls,表示了系统调用号到系统调用的映射关系。在syscall(void)中,通过trapframe->a7得到系统调用号,然后执行相应系统调用,即sys_sleep。
其实这里故意忽略了一些细节,包括上下文切换(用户态到内核态)以及内核具体的执行等。这一部分先不展开讲述,随着课程的深入再慢慢讲述。
代码部分的话:
- sleep.c和pingpong.c都很简单。
- prime.c则用父进程做为最开始的输入,然后子进程接收输入,并判断是否打印,然后继续转发输入到自己的子进程…
- find.c则参照ls.c实现,然后递归调用下。
- xargs需要注意空行和空格的分割,我的实现思路是先分割\n,然后再分割’ ‘,将得到的参数拼接在一起,最后再进行执行。
还有需要注意的是,局部变量在使用前要初始化,不然会导致脏值。