之前就看过netty的源码,但是由于netty调用栈极其复杂,细致地看每行代码很容易陷入思维混乱。本文虽然基于源码,但不完全依赖源码,希望以稍微偏上层的总结来理解netty的整体流程。源码版本为4.1.41.Final。
netty启动
这里仅介绍服务器端的启动过程(客户端的启动比较简单)。
1 | EventLoopGroup bossGroup = new NioEventLoopGroup(1); |
以上截取自netty-example中的EchoServer的源码。
b.group()...部分的代码比较简单,就是设置ServerBootstrap的启动属性。启动的核心方法是bind()。
1 | public ChannelFuture bind(SocketAddress localAddress) { |
首先会将PORT和本地IP进行组合构建InetSocketAddress对象并传入以上方法。可以看到bind的第一步是validate,主要是判断ServerBootstrap对象是否设置一些参数,如group、childgroup、channelFactory和childHandler。
1 | private ChannelFuture doBind(final SocketAddress localAddress) { |
在介绍前,这里先讲解一下netty的几个概念:
- NioEventLoopGroup可以理解为线程池,其中的每个EventLoop都对应一个线程。
- 每个EventLoop都有一个selector
- worker线程池中的每个channel都对应一个客户端连接。
- 所有的channel都是在对应的EventLoop中运行的,是n:1的关系。也就是说一个EventLoop中能运行多个channel,但一个channel只能运行在一个EventLoop中。
- 一个channel对应一个ChannelPipeline,ChannelPipeline中包含多个ChannelHandlerContext,每个ChannelHandlerContext都对应一个ChannelHandler。
接下来会忘以上代码中抽几个核心点进行讲解:
- initAndRegister():主要是创建并注册channel
- 创建channel
- 默认以使用反射创建NioServerSocketChannel,其实是对ServerSocketChannel的一种包装。
- 创建对应该channel的pipeline,并且创建两个ChannelHandlerContext(head和tail)
- 会设置感兴趣的类型(OP_ACCEPT),并设置为非阻塞。
- 初始化channel
- 设置channel选项和属性
- 向pipeline中添加ChannelInitializer(简称为CL1,不是b.childHandler中的那个),由于此时channel尚未注册,所以将CL1作为task添加到等待执行队列中(当channel完成注册后执行)。
- 注册channel
- 从boss线程池中选择一个EventLoop进行注册。
- 如果当前线程就是选择的EventLoop,就直接进行注册;如果不是,就向EventLoop提交一个注册任务。
- 需要注意的是channel注册时,并没有设置OP_ACCEPT事件。
- 注册成功后,唤醒等待执行的任务,即上文提到过的CL1。
- CL1先往pipeline中添加LoggingHandler,再添加一个ServerBootstrapAcceptor。
- 唤醒注册成功的ChannelPromise的监听者,简称B,下文会提到。
- 唤醒pipeline中各个ChannelHandler的channelRegistered方法。
- 创建channel
- doBind0():由B调用,从tail到head依次唤醒ChannelContext的bind方法,注意head会真正执行bind地址,即
javaChannel().bind(localAddress, config.getBacklog());。绑定完成后,会从head开始执行channelActive方法。 - 激活channel:待其余context的channelActive方法执行完毕,执行head的readIfIsAutoRead(),层层递进后设置selector监听OP_ACCEPT。
上述的说明没有源码配合的话,就会显得很难理解。但是配合源码的话,又会显得过于啰嗦,太着重于细节。这里抛开代码,对netty启动做一个总结。
netty的启动过程掺杂着各种异步调用,但实际上channel可以归类为4个状态:
- Init:创建了channel需要的pipeline,以及其中的tail和head,并且设置channel选项和属性。此时虽然有了需要绑定的地址,但是实际并没有进行绑定,并且channel没有注册到相应的EventLoop。
- Registry:将channel注册到了EventLoop中,然后在对应的pipeline添加了设置的handler和ServerBootstrapAcceptor(用来创建新连接)。此时channel并未bind地址。
- Bind:从tail到head链式执行bind方法,待全部完成后,对channel进行地址绑定。注意此时,该channel还未工作,因为一开始设置的socket兴趣类型为0(即不对任何io感兴趣)。
- Active:从head到tail执行channelActive方法,全部完成后,设置socket兴趣类型为OP_ACCEPT。至此,channel开始进行工作。
简单提一下服务端接收客户端连接:首先服务器接收到连接,使用accept创造新的socket,然后invokeChannelRead,直到ServerBootstrapAcceptor的channelRead,将新的socket放入worker线程池。
另外客户端的状态变化为Init->Registry->Connect->Active,需要注意的是当Connet成功后,才会转为Active状态。
netty的FastThreadLocal
netty中的FastThreadLocal是PoolThreadCache、Recycle的基石,从它的名字就能看出,它起到ThreadLocal的作用,并且比ThreadLocal更快。那么JDK中的ThreadLocal存在什么问题,使得netty自己写了一个类来替代它呢。
首先ThreadLocal是通过在Thread内部的ThreadLocalMap类型的threadLocals实现的。在调用ThreadLocal.get()会在当前线程的threadLocals中生成一条包含有ThreadLocal对象和Value的entry。由于不同Thread中的threadLocals不同,所以对于同一个ThreadLocal,相应的value就会不同,从而实现了线程间的隔离。但是Thread存在很多不足,这里将通过JDK8中的ThreadLocal源码来讲解。
1 | private void set(ThreadLocal<?> key, Object value) { |
这里截取了ThreadLocalMap的set方法(由ThreadLocal.setInitialValue()调用),根据代码可以看出:
- 根据nextIndex方法可以看出ThreadLocal解决哈希冲突的方法是线性探测,所以查找的时候也是根据线性探测法查找。当使用多个ThreadLocal时,哈希冲突的概率会变大,这时ThreadLocal的get或set速度都会更慢。
- 其实ThreadLocalMap中每个entry的key是WeakReference<ThreadLocal<?>>。当ThreadLocal使用完毕后,并且没有remove,但是此时entry中的value还存在着,因此会导致内存泄漏。事实上,ThreadLocalMap也针对此提供了一些清除机制,也就是在每一次set或getEntry后都会清理一部分key为null的entry。只是这种机制并不能保证完全避免内存泄漏。
接着我们再来看看FastThreadLocal:
1 | public final V get() { |
可以看到FastThreadLocal引入了新的InternalThreadLocalMap,InternalThreadLocalMap的get也很有意思。
1 | public static InternalThreadLocalMap get() { |
一般来讲FastThreadLocal是和FastThreadLocalThread(Thread子类)配合使用的,但FastThreadLocal也提供了与Thread的兼容,其实就是使用ThreadLocal在每个线程中存一个InternalThreadLocalMap,然后再执行其他操作,相当于多执行了一次调用。但是需要注意的是,只有搭配FastThreadLocalThread,FastThreadLocal才会快过ThreadLocal。
InternalThreadLocalMap以数组作为底层存储结构,初始是大小为32的Object[]。
1 | private V initialize(InternalThreadLocalMap threadLocalMap) { |
更细致的代码不继续展开,大的改动就是去掉了弱引用,并且将所有用过的FastThreadLocal都存储起来。当FastThreadLocal.remove()时,就会清空Object[]相应下标的值,并且也在removeSet中除去。那么如果没有remove,那么FastThreadLocal是怎么释放的呢?
1 | // FastThreadLocalThread.java |
这也就是为什么推荐FastThreadLocalThread和FastThreadLocal配合使用的原因了。在线程运行结束后,就会调用removeAll,释放内存。但其实有点牵强,也就是在线程运行时,并不会清除掉无用的value,直到线程运行结束,才会removeAll。但是原生的ThreadLocal在线程运行结束后,也会在由GC进行清除的。
所以,总的来说FastThreadLocal相比原生ThreadLocal有以下两个优点:
- 查询速度快:采用下标查询法,O(1)的时间复杂度。
- 显式释放内存:相对于GC行为的不确定性。(这个优点我个人觉得很勉强)
netty的ByteBuf
关于ByteBuf的使用,已经有很多博客讲过了。这里主要讲解下池化的ByteBuf是怎么获得的。
netty在接收read数据时,会自动使用AdaptiveRecvByteBufAllocator类来创建ByteBuf(创建动作实际上是交给PooledByteBufAllocator执行的)。
这里需要注意的是:池化的ByteBuf需要通过ReferenceCountUtil.release(msg)手动回收或者直接传递至TailContext进行自动回收。
AdaptiveRecvByteBufAllocator仅仅对申请的ByteBuf做了限制。
1 | static { |
也就是BufSize={16, 32, 48, 64, …, 512, 1024, 2048, …, 2^30}。初始大小为1024。
具体的创建内存、分配ByteBuf、管理ByteBuf池的过程则是netty内存池的核心。默认使用PooledByteBufAllocator.DEFAULT分配堆外内存(也就是直接内存)。
至于具体的创建buf的过程则是netty的核心(池化内存)。
netty使用PoolThreadCache和Arena进行内存分配:
- Arena:由多个线程共享,是实际上进行内存申请和分配的核心。
- PoolThreadCache:由单个线程独享,顾名思义,是内存的缓存,当缓存中有内存块的存在时,会先在缓存中查找是否存在符合的内存块。
举个例子来讲解这两者之间的关系:当线程第一次申请ByteBuf时,PoolThreadCache是空的,所以在其中找不到合适的内存块;线程接着向Arena发起申请,Arena响应申请后,返回ByteBuf;线程使用ByteBuf完毕后,进行释放,ByteBuf被释放后先进入PoolThreadCache中(等到分配次数达到一定次数后才会进入Arena中)。
那么Arena是怎么管理内存块呢?主要是通过PoolChunkList和PoolSubpage来进行管理。
- PoolChunkList:管理Chunk,每个Chunk内部使用完全二叉树结构管理page,其大小由pageSize和maxOrder(可以认为是最大深度)。
- pageSize默认为8K,maxOrder默认为11,所以默认情况下chunk大小为16M。即高度为12的完全二叉树,共有4095个结点(其中2048个叶子结点,每个代表一个page)。
- 该完全二叉树的底层存储结构为数组,并且下标从1开始,所以数组大小为4095+1。
- 树中每个非叶子结点的内存大小等于左右子树的内存之和。
- 数组中结点序号对应的是该结点的深度,深度为1,即可分配16M;深度为2,分配8M…当值为12时,表示该结点已经分配。
- PoolSubpage:针对小于page的内存进行管理
- tinySubpagePools:大小的基本单位为16字节,16、32、48、…、496。
- smallSubpagePools:大小的基本单位为512字节,512、1024…4096。
- 针对tinySubpagePools和smallSubpagePools的每个规格,都维护着一条链表。
在具体分配时,需要根据需要分配的大小判断使用page还是subPage:
- page:在chunkList中查找可用的chunk进行分配,若没有,则重新创建一个chunk。
- subPage:区分选择tinySubpagePools还是smallPagePools,看是否有可用的PoolSubpage,如果有的话就直接分配;如果没有,则分配一个page,参见上条。
关于chunk、tinySubpagePools和smallSubpagePool的数据结构和管理可以看参考博客,我就不重新画图了,不得不说netty的设计特别巧妙。
netty使用心得
以下是使用netty时的一些问题和心得总结。
通过心跳机制关闭长连接
可以使用IdleStateHandler通过读/写超时事件进行触发,但是IdleStateHandler只能在连接有效时使用,不适用于异常中断情况。
对客户端异常中断进行处理
netty在检测到连接中断后会自动关闭channel,所以可以在channelHandler中重写channelInactive、channelUnregistered和channelRemoved(这三个方法依次执行)。
在接收新连接时创建2个channel
有时接收新连接时只创建一个channel,有时创建2个(第一个很快关闭)。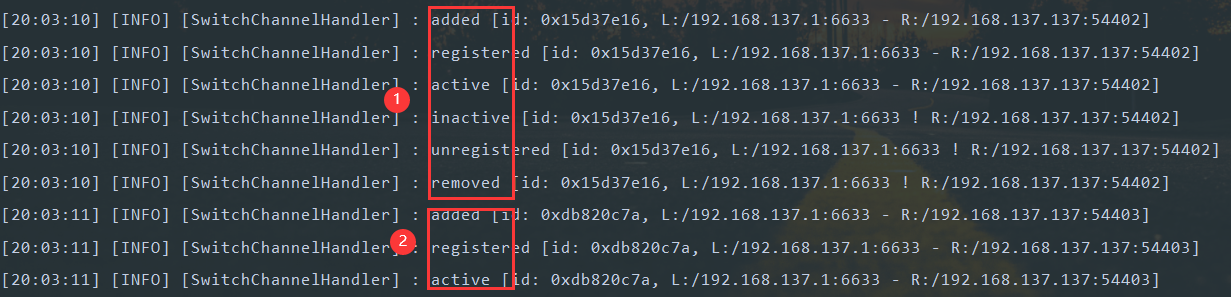
可以看到创建了2个channel(测试环境win10,jdk8),具体原因尚不清楚,等以后有时间再看看。