动机
写这个项目主要是因为两个原因:
- 这个项目的前身(pnpl-c)是实验室的祖传项目,是用C语言写的,自己后来也在这个原型上面进行过一些扩展。在使用过程中,我发现了pnpl-c存在的一些问题,包括一些bug和没有妥善考虑的地方,所以想写一版更加完善的pnpl。并且,因为自己的主要开发语言是java,也想用一个所以想用java对pnpl-c进行重写。
- 自己的毕业论文准备做容错控制器,所以想在pnpl-c的功能基础上扩展容错能力,包括应对拓扑变化,流表管理,控制器单点故障等。
基于这两个原因,就有了pnpl-java这个项目,以下简称pnpl。
介绍
pnpl是一个应用于SDN(Software Defined Networking)领域的控制器,使用POF(Protocol-Oblivious Forwarding)协议管理POF交换机。
可能大家不太清楚SDN到底什么,我在这里简单介绍一下。
- 当前传统计算机网络以大量的路由器、交换机和其他网络设备作为物理基础设施,并在其上支撑着各种复杂的协议。每次适配新协议,网络运营商就需要重新配置网络设备,十分繁琐且容易出错。也因为这个原因,从TCP/IP协议族诞生以来,之后网络新协议的研究变得迟缓僵化,难以发展。
- SDN则是将交换设备从变为可编程交换机,将控制与转发分离。可编程交换机负责转发数据包,而具体的转发行为则由控制器下发。也就是说,一开始交换机并没有支持任何协议的功能,只有当控制器下发流表后,交换机才能对数据包进行流表匹配,从而执行特定的转发动作。
可以看到,SDN是灵活的,通过向交换机下发新流表就可以使网络适配新协议,配置轻松简单。另外,相对于传统网络的分布式架构(每个网络设备都是单独个体,单独处理流入的数据包),SDN是集中式架构,能提供网络的统一视图,对于网络资源的分配和优化具有巨大的潜力。
个人认为,将传统网络全部替换为SDN网络是不现实的,SDN的最合适的应用场景还是数据中心(Fackbook和Google都在他们的数据中心使用了SDN网络),不管是流量工程还是某些特殊场景,都可以通过灵活配置得以实现。
而POF协议是一种SDN控制器与交换机之间的交互协议,其最大特点就是将数据包中的各个域都表达为(offset,length),使得交换机能够处理自定义协议。
架构
pnpl可以通过用户提供的数据包头部规范和策略来处理自定义协议,具体可看PNPL论文
pnpl
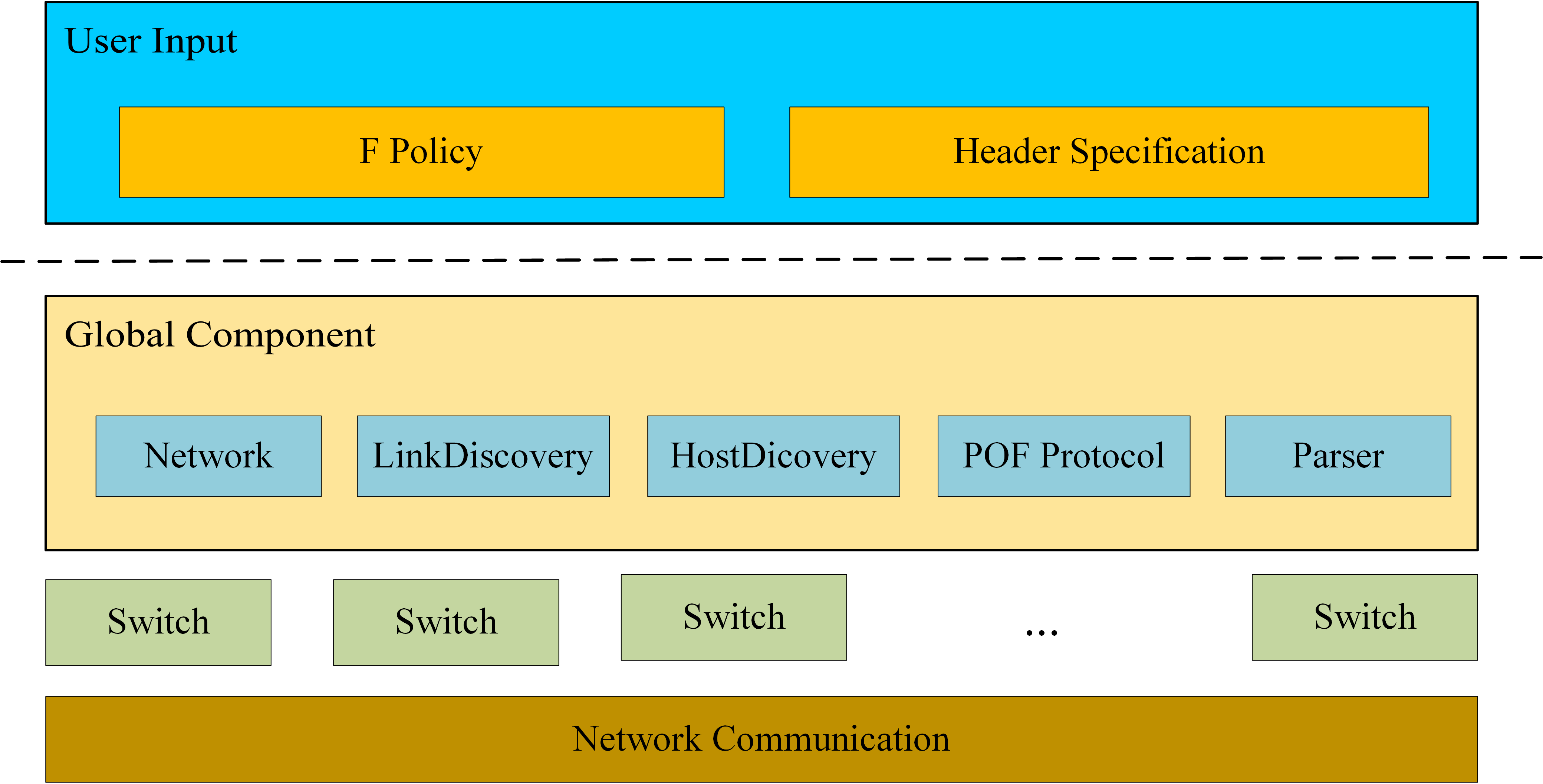
- 最底层是网络通信,这里使用Netty来简化网络编程,主要负责将收到的字节流转化为不同类型的POF消息。
- Switch代表和控制器连接的交换机,保留该交换机的流表信息,并且执行特定的策略。
- 全局组件主要分为:
- Network:维护虚拟网络元素,如交换机、主机和链路,形成网络拓扑的统一视图。
- LinkDiscovery:负责一开始的拓扑创建和后续的拓扑更新。
- HostDiscovery:负责发现和交换机相连的主机。
- POF Protocol:POF协议库,封装了POF协议相关的类。
- Parser:解析用户提供的头部规范,提取出头部信息。
用户
对于用户来说,需要提供头部规范和策略:
头部规范
header ipv4;
header ipv6;
header arp;
header icmp;
header igmp;
header tcp;
header udp;
header ethernet {
fields {
dl_dst : 48;
dl_src : 48;
dl_type : 16;
}
next select (dl_type) {
case 0x5555: sdnp;
case 0x0800: ipv4;
case 0x0806: arp;
case 0x86dd: ipv6;
}
}
header ipv4 {
fields {
__ver : 4;
__ihl : 4;
__tos : 8;
__len : 16;
__id : 16;
__flag : 3;
__off : 13;
__ttl : 8;
nw_proto : 8;
__sum : 16;
nw_src : 32;
nw_dst : 32;
__opt : *;
}
length : ihl << 2;
checksum : sum;
next select (nw_proto) {
case 0x01 : icmp;
case 0x02 : igmp;
case 0x06 : tcp;
case 0x11 : udp;
}
}
start ethernet;以上是一个简单的头部规范,指明了每个头部所包含的域、头部长度和上层支持的协议等,并且规定了起始头部为ethernet。Parser能对头部规范进行词法分析、语法分析,进而解析各个头部信息以及上下层关系。
策略
public class Ipv4Forward extends AbstractPolicyAdapter {
@Override
protected List<Hop> f() {
gotoNextHeader();
gotoNextHeader();
String header = readHeaderName();
if (header.equals("ipv4")) {
Value srcIp = readPacketField("nw_src");
Value dstIp = readPacketField("nw_dst");
if (srcIp == null || dstIp == null) {
return null;
} else {
return getPath(getHost(srcIp.intValue()), getHost(dstIp.intValue()));
}
}
return null;
}
}用户通过编写继承于AbstractPolicyAdapter的策略类,即可调用pnpl提供的api来处理网络数据包,上述代码中的gotoNextHeader和readPacketField分别是进入下一层头部和读取头部中某个域的功能,getHost则是获取某个主机,getPath则是计算两台主机之间的路径,通过这些API,自定义策略就能对数据包完成处理。

- 监测交换机的连接,开始进行POF协议的握手,将POF交换机抽象为Switch对象,后续的消息上报都由该对象进行处理。
- Switch启动工作后,首先向LinkDiscovery注册其上的端口,由LinkDiscovery开始链路发现工作。
- LinkDiscovery记录端口信息,并根据端口信息构建LLDP报文,再发送给交换机从该端口发出构建的LLDP报文。
- 当Switch收到LLDP报文后,交由LinkDiscovery进行处理,通过对LLDP报文进行解析得到该报文的源交换机和源端口,从而构建出(交换机,端口)-(交换机,端口)的链路,并注册到Network中。
- 每个端口注册到LinkDiscovery后都会进行三次链路发现,若无任何回应,则会认为该端口无连接到其他交换机的链路,后续的链路更新方法可自由定义,较普通的方法是周期性地向各个端口发送LLDP报文。
- Switch若是收到ARP报文后,则会交由HostDiscovery进行处理。
- 若是ARP请求报文,则先注册host到Network里,然后查询network中是否存在ARP请求的目标主机:
- 若有,则构建ARP响应报文。
- 若没有,则在网络中洪泛ARP请求。
- 若是ARP响应报文,则注册host到network中。
- 若是ARP请求报文,则先注册host到Network里,然后查询network中是否存在ARP请求的目标主机:
- 收到普通数据包(非LLDP和ARP),则交由AbstractPolicyAdapter进行处理:
- 首先查询TraceTree,若有对应的分支,并且该分支的流表已被删除,则根据该分支下发流表。
- 若无TraceTree分支,说明该数据包为第一次处理,则准备调用用户策略进行处理:
- 预处理工作,清空events列表。
- 用户策略中每次调用pnpl的api,则会生成对应的event,加入到events中。
- 将events列表转化为TraceTree分支。
- 解析TraceTree分支并下发流表规则至对应的POF交换机。
- 将TraceTree分支加入到该Switch的TraceTree中。
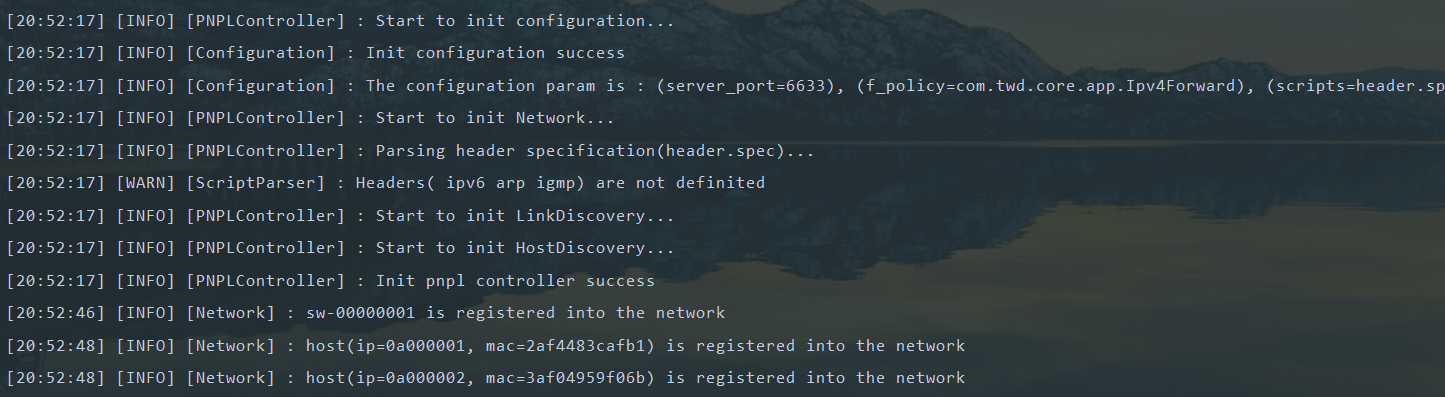
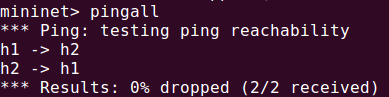
pnpl启动(日志系统使用的是SLF4J+logback):