MapReduce分析
之前介绍了Google的GFS,链接为GFS 分析,现在介绍另外一驾马车MapReduce。
MapReduce编程模型
MapReduce首先是一个编程模型,通过Map和Reduce函数,利用一个(key1, value1)的输入集合来产生(key2, value2)的输出集合。注意,这里的输入和输出集合的key不一定相同,特意用key1和key2标注出来了。map函数将输入集合变为中间集合,reduce函数将中间集合变为输出集合。下面使用一个MapReduce论文上的例子来进行说明:
map(String key, String value):
// key : document name
// value : document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key : a word
// values : a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));这个例子是统计多个文档中每个单词出现的次数,假设现有两个文件1.txt和2.txt,他们的内容如下:
1.txt : hello world hello world world
2.txt : world hello world hello hello那个输入集合就是{(1.txt, 1.txt content), (2.txt, 2.txt content)},MapReduce的处理流程如下:
- map函数将输入集合转化为中间集合,中间集合内容为:{(“hello”, [“1”, “1”, “1”, “1”, “1”]), (“world”, [“1”, “1”, “1”, “1”, “1”]}
- reduce函数对中间集合进行遍历,得到输出集合{(“hello”, “5”), (“world”, “5”)}
MapReduce流程
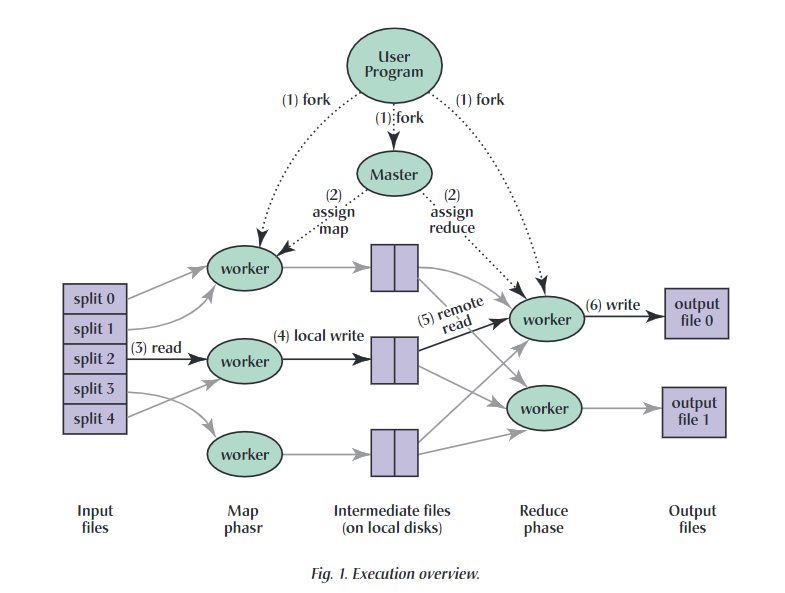
MapReduce的整体流程如上图所示(图片来源于MapReduce论文):
- 用户程序首先调用MapReduce库将输入文件分为M个数据片段,每个数据片段的大小一般为16MB到64MB。然后在集群中创建大量的程序副本。
- 这些程序副本中有一个非常特殊,它就是master。剩下的都是worker,执行由master分配的任务(包括M个map任务和R个reduce任务)。map会将一个map任务或reduce任务分配给空闲的worker。
- 被分配到map任务的worker读取对应数据片段的内容(M个map任务和M个数据片段一一对应),从输入的数据片段中解析出key/value pair,然后传给用户定义的map函数进行执行,将中间结果缓存在内存中。
- 缓存中的中间结果key/value pair通过分区函数分为R个区域,之后周期性地写入到本地磁盘。缓存的key/value pair在本地磁盘上的存储位置将被传给master,由master将这些位置告知给reduce worder。
- reduce worker收到master发来的数据存储信息后,使用rpc从map worker上读取这些缓存数据。当reduce worker读取了所有的中间数据后,通过对key进行排序使得具有相同key值的数据聚合在一起。由于许多不同的key值会映射到相同的reduce任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,就需要在外部进行排序。
- reduce worker程序遍历中间数据后,对于每个唯一的key和其对应的中间value的集合交给用户定义的reduce函数进行执行。reduce函数的输出将被追加到所属分区的输出文件。
- 所有map和reduce任务完成后,master唤醒用户程序,此时mapreduce才算调用完成。
完成任务后,最后的结果仍是存放在R个输出文件中的(对应R个reduce任务)。一般情况下,这些输出文件不需要合并为一个文件。
MapReduce细节
这一部分主要是以问题形式来深入了解MapReduce的实现细节。
对M,R的划分
M指的是对输入数据划分为M块,并且对map过程划分为M个任务。R值的是对中间数据划分为R个分区,并且对reduce过程划分为R个。
论文中对M和R的考虑是,M和R应当比集群中worker的机器数量要多,这样每台机器都能执行大量不同任务来提高集群的动态负载均衡能力。合适的M,需要使得每一个独立任务都是处理16M到64M的输入数据(这样也能对每个map任务得到的中间结果缓存在内存中)。R值通常由用户指定,通常使用对应的分区函数(比如hash(key’) mod R)来对中间数据进行划分,从而输送至R个reduce任务。google通常会在2000台worker机器上,执行M=200000,R=5000的MapReduce任务。
这里我觉得对于M有更多的细节考虑:不恰当的划分过程可能会产生数据倾斜现象。比如有10个文件(其中1个10G,另外9个都是1G)要划分成10个块,完成单词统计,那么按文件数量来划分就会出现某个map任务要处理10G数据,远超其他map任务。所以按照实际的数据量来划分显然更恰当,但是在划分过程中需要注意划分的正确性,比如某次划分刚好将一个单词分成了两半,那么就会影响最后结果的正确性。
map任务和reduce任务是并行么?
我对论文的理解是map和reduce之间不并行。回顾整个MapReduce的工作流程,可以看到reduce任务是读到所有属于该分区的中间数据中,才开始计算,如下图所示: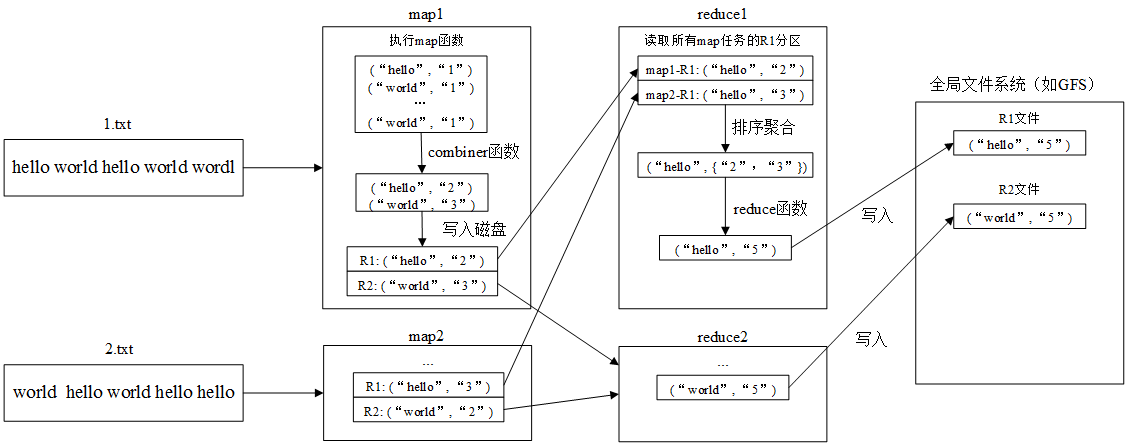
这里以之前的例子细致说明了map任务和reduce任务的执行过程。图中略去了map任务向master汇报,再由master通知reduce的过程。这种工作模式的缺点在于map任务和reduce任务并不能同时执行,因为每个reduce任务都在等待特定分区的中间数据,而每个map任务都有可能有该分区的数据,所以需要一直等待所有map任务完成为止。map任务之间相互并行,每个map任务完成时,都会向master汇报分区数据对应的存储位置。master会将这些位置信息告诉给相应的reduce任务。
我认为这样设计可能是因为MapReduce完成的时间取决于最后一个map任务完成的时间和最后一个reduce任务完成的时间(因为map之间并行,reduce之间并行),并且这样设计实现起来也较为简单,如果考虑reduce和map之间的并行,需要考虑更加复杂的情况。
combiner函数的作用
combiner函数的执行位置可见上图,一般等同于reduce函数。因为map生成的中间数据中key可能会有很大重复,所以相当于map先在本地进行一次reduce函数,压缩数据,从而节省了网络带宽资源。
输入数据是怎么送达worker机器
其实MapReduce最好建立在GFS的基础上,这样本身GFS的每个chunk为64MB,且分布在不同的机器上,刚好可以当做map worker。当然也可以将原始数据划分后,通过网络送达到map worker,但是整个执行流程会很依赖于网络带宽。
master的作用
master会存储每个map和reduce任务的状态(空闲、工作中或完成),以及worker机器的标识。并且其作为map和reduce的桥梁,将会把各个分区的位置信息传递给reduce任务。
work故障如何处理
master会定期ping worker,以此来判断worker的存活。一旦一定时间内没收到worker的回复,master就会认为这个worker已经死掉,然后这个work执行的map/reduce任务将会被重新标记为初始状态,交由其他worker完成。
落伍者
影响一个MapReduce的总执行时间最通常的因素是“落伍者”:在运算过程中,如果有一台机器花了很久的时间才完成最后几个map或reduce任务,导致mapreduce操作的总执行时间超过预期。针对此,MapReduce的处理策略是当一个MapReduce操作接近完成的时候,master调度备用(backup)任务进程来执行剩下的且处于处理中状态(in-progress)的任务。无论是最初的执行进程、还是备用(backup)任务进程完成了任务,都会标记这个任务已经完成。