GFS(Google File System)源于论文《The Google File System》,是Google分布式技术三驾马车之一。了解GFS,对了解分布式文件系统会有帮助。这篇博客主要从论文角度讲解GFS,并以一个小Demo作为演示。
GFS论文理解
GFS作为Google的分布式文件系统,根据Google自身业务场景的特性(大部分文件操作都是追加写,覆盖原有数据的情况比较少等),做了相应调整和优化。本文不会解释GFS论文的所有内容,而是选取其中的重点进行讲解。
GFS Architecture
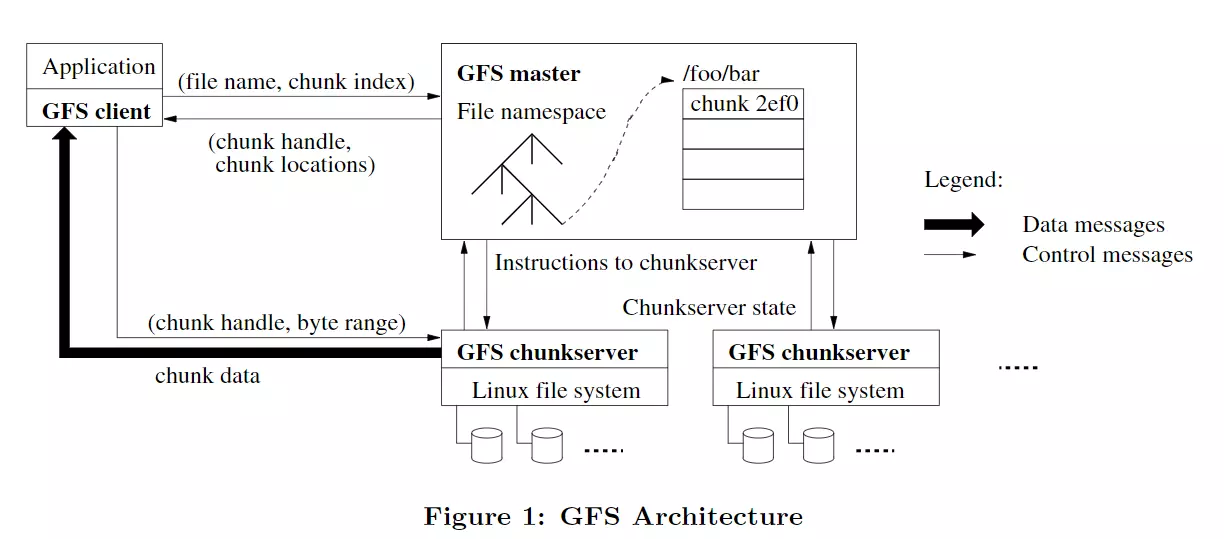
- GFS chunkserver: 顾名思义,就是存放chunk的服务器。为了可靠性考虑,一个chunk会被同时存储在多个chunk server上。
- master:包含了文件系统的所有元数据,包括命名空间、访问控制信息、file到chunk的映射关系和chunk存放的位置。可以说master是整个GFS的大脑,它知道所有的信息,并且系统级的活动都需要它的参与(比如chunk lease管理、垃圾回收和chunk迁移等)。另外,master还会以心跳包的形式与每个chunkserver保持连接。
- client:与master和chunkserver进行交互,从而完成数据的读写。其最后的呈现结果是一个专用库,开放了一些API供application调用。
- application:上层应用,只需要调用client库的API就可以完成读写。打个比方appl调用了client库的open(“123.txt”),client库就会在内部通过一系列交互,打开与该文件相关的chunk。
Single Master
GFS中单个master的优势在于设计和实现简单。但是需要避免的是,在文件读写中降低master的参与度。打个比方,如果多个client在读写时全程都需要master的参与,那么将形成多对一的关系,master所要承担的压力会急剧上升,从而成为系统的瓶颈。GFS降低master参与度的方式是:在请求时,应用把(filename,offset)传给client,client转换成(filename,chunk_index),再传给master。master接收到请求后,会把对应chunk的(chunk handle,chunk location)反馈给client。之后的读写都由client和chunkserver交互完成。也就是说对于一次读写,client只与master进行一次交互。
- chunk index = offset / chunksize
- chunk location就是指这个chunk在哪些chunkserver上
Chunk Size
GFS的chunk大小设置为64MB,其优点和缺点都如下所示:
- 优点:
- 当chunk size较大时,可以减少client和master的交互次数。比如client申请读read(‘1.txt’, 0), read(‘1.txt’, 4096), read(‘1.txt’, 128000),这三次读请求都在1.txt中的第一个chunk,所以实质上client只与master进行了一起交互,即请求1.txt的第一个chunk的位置信息。
- chunk越大,那么在该chunk上执行的操作也就越多,那么可以通过持久性TCP连接来减少网络开销。
- 减少了存储在master中的metadata的大小。比如所有文件大小总和是2560M,如果将chunk size设为32M,则需要80个chunk,也就是80个对应metadata;将chunk size设为64M,则只需要40个chunk,metadata的数量减少了一半。越少的metadata就意味着能将其直接放在master的内存,这样能加快master对client请求的响应速度。
- 缺点:
- chunk size越大,也就是说很多小文件可能只有一个chunk,那么如果多个client同时访问这个文件,那么存有该chunk的chunkserver将面临高额的负载,即hot spots问题。对于这个问题,Google的做法是对于这种chunk进行更多的备份,并且通过批处理队列系统错开应用程序的启动时间。另外,Google也认为允许client从其他client读取数据可能会是一个长期方法。
Metadata
GFS master存储着三种metadata:
- 文件和chunk的namespaces:是文件系统的逻辑元数据,包括层级目录结构以及访问控制等
- 文件到chunk的映射关系:通过文件名查找到对应的chunks
- 每个chunk的位置信息:有几个副本,这些副本在哪些chunkserver上
对于前两者,master会记录到操作日志并复制到远端以保证其持久化。操作日志会存储在master和多台远程机器上,只有当operation log在master和远程机器上都写入成功后,master才会响应client的请求。
关于chunk的位置信息,master并不做持久化保存,因为chunkserver很容易出现宕机等故障。在每次master重启或者有新的chunkserver加入时,会要求对应的chunkserver汇报其包含的chunk信息。
对于metadata,master将其全部存在内存中,这样做的好处在于读取和更新metadata的速度很快。至于master的内存会不会成为系统的瓶颈,因为一个64MB的chunk的metadata不会超过64B,因此64G内存的master可容纳1Gchunk的metadata,如果内存真的成为瓶颈,也可以通过增加内存来解决。
System Interactions
这部分主要讲解GFS的交互过程。
leases and Mutation Order
lease是分布式系统常用的一种机制,lease相当于一种授权,是由颁布者授予的某一有效期内的承诺,lease的接受者将在lease到期前获得“特权”。
之前也提到了master只负责告诉client请求的chunk所在的chunkserver,后续的读写流程master一概不参与。那么考虑这样一个问题,client该怎么与chunksever交互,并且对该chunk的写都同步到其他副本上。针对这个问题,GFS在多个包含同个chunk的chunkserver中选择一个作为primary,授予其lease保证其在一定期限内一直维持primary的身份。而client就与这个primary打交道。
- client先询问master关于这个chunk的primary位置和其他保存副本的chunkserver位置。
- master回复client后,client会缓存primary和其他副本的位置直到lease失效。
- client将数据发至所有包含副本的chunkserver(包括primary),这个顺序是随client自己定的。所有的chunkserver在接收到数据后先不更新,而是放入LRU缓存池。
- 当确认了所有的chunkserver都收到了数据后,client就向primary发送写请求。primary会先进行写操作,然后为这次写请求分配序号,保证从多个客户端的并发写请求有唯一的操作顺序,也保证了副本写入数据的顺序都是一样的。
- primary将写请求转发至所有副本,转发顺序由primary指定。
- 副本写成功后会将响应发给primary
- primary再将响应发送给client。
当错误发生时,即某些副本未能完成写操作,就会直接发送失败信号给client。client对此的处理是重新发送这个写请求,即重复3~7步骤。另外,当写的内容较大时,client会将其分割成多个写操作。
Data Flow
回顾之前的写流程的第三步,client需要将数据发送至所有的副本,但是并不是通过由client直接对不同的副本发送消息完成,而是以一种pipeline的方式完成的。
- client选择离它最近的chunkserver A发送数据。
- chunkserver A收到数据后,转发给离它最近的另一个chunkserver(即primary)。
- primary收到数据后,又转发给chunkserver B。
也就是通过就近原则,不断地转发数据,直到所有的chunkserver都收到了数据。这种方式有效利用了所有机器的网络带宽。
Atomic Record Appends
追加写的流程与写流程差不多,主要有以下区别:
- client把数据推送到所有副本的最后一个chunk。然后发写请求。
- primary先检查最后一个chunk是否能容纳当前写请求。如果可以,就进行写操作;否则,会将最后一个chunk填充到64MB,然后告诉client需要在下一个chunk上重新发起写请求。(显然,这也就意味了GFS不会接受64MB以上的追加写申请,实际上,GFS的追加写内容大小不能超过1/4个chunk size)
Consistency Model
读到这里,已经对GFS的交互有了一定了解,接下来我们就来看看GFS的一致性模型。
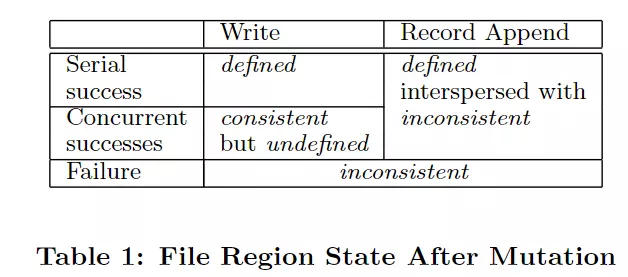
- consistency:所有client无论从哪个副本读,都能看到相同的内容
- defined:当一个文件区域发生修改后,client可以看到修改的所有内容。
接着我们对表格中的几种情况进行分析:
- write(serial success):串行写(同一时刻只有一个写请求),返回成功时,所有的副本都更新了数据,所以客户端都能看到这次操作写入的数据,所以是defined。
- write(concurrent success):并发写,返回成功时,由于写的顺序由primary来决定,并且多个写请求可能有区域重叠,最终完成的数据可能是多个写操作叠加起来的结果,所以是consistency和undefined。
- write(failure):写操作失败时,有的副本写入了数据,有的没有,所以是inconsistent。
- Record Append(serial success and concurrent success):由于内容都是追加至末尾,那么肯定是defined。但是假如其中经历了一次failure,然后重试之后才成功,那么状态就会是interspersed with inconsistent。
- Record Append(failure):部分追加成功,部分失败,所以是inconsistent。
Master Operation
master的功能包括namespace operations,make placement decision,create new chunks and hence replicas等等。
Namespace Management and Locking
master的每个操作都需要获得一些列的锁,其实质是基于文件路径的读写锁。比如,client要创建/home/usr/new_file,那么就需要获取/home,/home/usr的读锁和/home/usr/new_file的写锁。
Replica Placement
把每个chunk的副本分散在不同的机架上,从而利用多个机架的带宽,并且提高chunk的可靠性(避免机架级故障)。
Creation, Re-replicaton, Rebalancing
在创建chunk时,会根据多种考量来选择合适的chunkserver,比如选择磁盘空间利用率低于平均值的chunkserver等。
当一个chunk的副本数少于预期的时候,需要增加副本的数量。
还有通过检查副本分布情况,然后调整更好的磁盘使用情况和做好负载均衡。
Garbage Collection
GFS删除文件后,并不会马上进行物理删除,而是在定期的清理行为中才会对可删除的文件进行清除。具体的清除规则和过程这里不多讲。
High Availability
GFS通过fast recovery和replication来实现高可用性。
- fast recovery:指的是master和chunkserver都能在几秒内完成启动。
- replication:也就是多副本,GFS中对chunk、master的operation logs等都会进行多副本处理。
最后,再说明下,chunkserver会通过checksum来验证数据是否损坏。每个chunk被分为64KB的块,每个块有一个32b的checksum,checksum会在chunkserver的内存和日志中存储。对于读请求,chunkserver如果检测到一个block的checksum不对,就会报错给client和master。client就会从另一个副本读取消息,master也会重新复制一个副本(复制完成后,删除这个出错的副本)。
GFS Demo
根据GFS的论文思想,我用java语言实现了一个简单GFS Demo,整个demo放弃了网络通信和一些细节实现,主要就是直观描述了create,write,read调用的过程,该demo已经放在了我的github上,链接地址是gfs demo。下面的代码展示都略过了不重要的代码。
GFS Demo Element
这里我在element包下创建了三个类,ChunkRequest,ChunkMetaData和Chunk。
ChunkRequest
ChunkRequest主要包括文件名和对应的chunk index。当client收到外部的读写请求时,client计算出原始offset对应的chunk index,并和filename组装成ChunkRequest,通过ChunkRequest向master发起请求,获取对应chunk的metadata。
1 |
|
ChunkMetadata
这里设定的metadata的大小是1024KB, 这里的metadata没有论文里那么细致,仅仅是简单地记录了chunk handle和存放的chunkserver。
1 | public class ChunkMetadata { |
Chunk
chunk本质上也是一个文件,这这里chunk是一个最大容量为1024KB的文件。同时chunk也是read和write动作的真正执行者。
1 | public class Chunk { |
GFS Demo Role
role包下是整个demo的重点,包括了Master,Client和Chunkserver。这里副本的个数设为3。另外,这里的create和write都需要primary的参与。
Client
client受外部调用,通过与master和chunkserver的交互完成读写任务。
1 | public class Client { |
Master
master主要负责响应client的metadata请求,已经primary lease的授权,这里的lease无有效期限制。
1 | public class Master { |
Chunkserver
chunkserver承担了create、read和write的大部分工作。
1 | public class ChunkServer { |
Demo
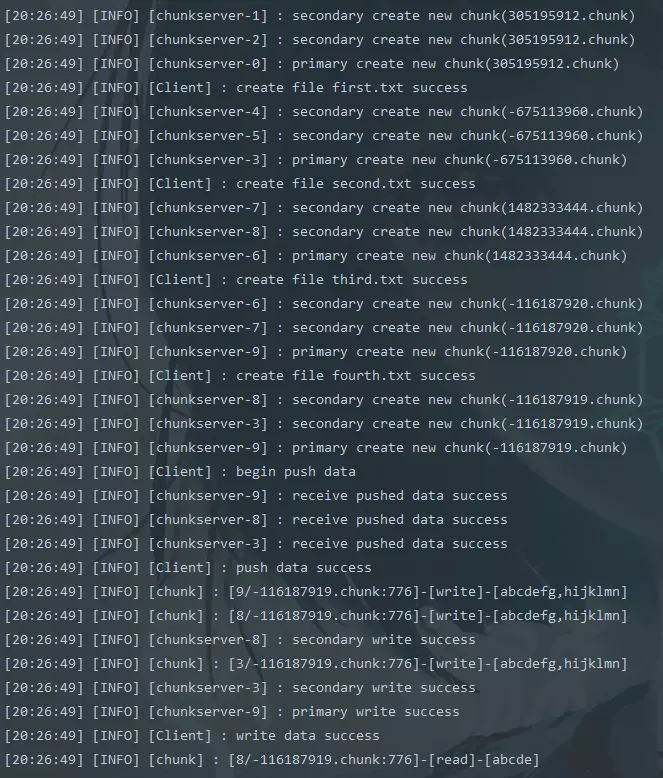
测试上述create,write,read流程。
1 | public class Demo { |
结果如下所示: