Slf4j源码分析
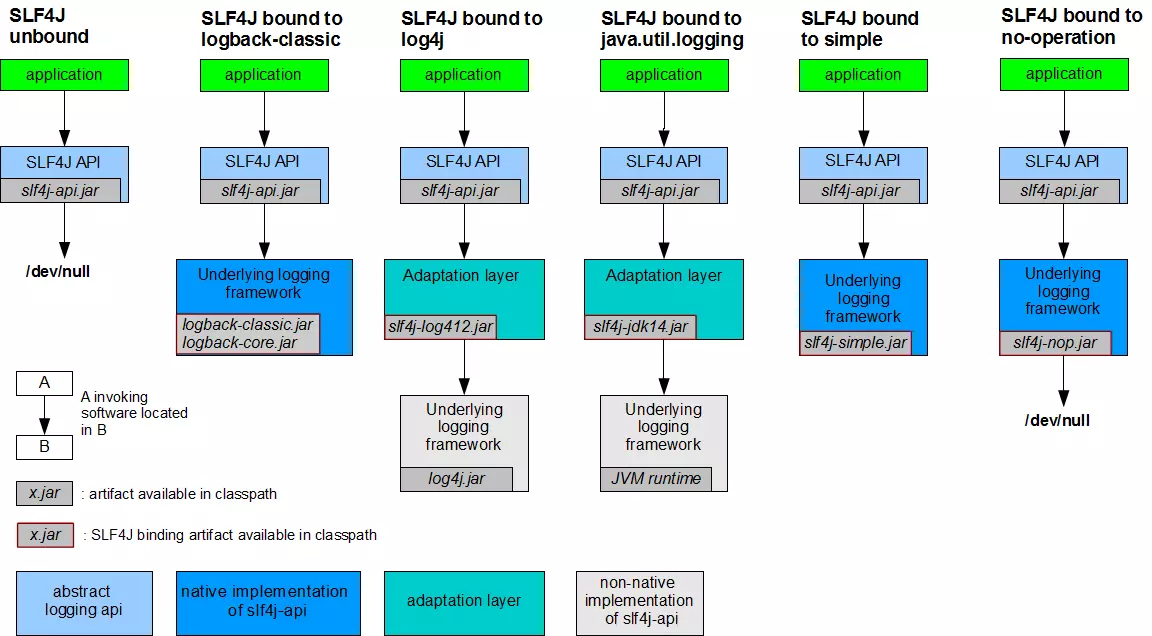
Slf4j(Simple Logging Facade for Java)是对不同日志框架的简单门面,允许用户自由选择具体的日志实现。
1 | import org.slf4j.Logger; |
Slf4j静态绑定
getLogger方法是所有使用的开始
1 | public static Logger getLogger(Class<?> clazz) { |
这里我们先从getLogger方法看起。
1 | public static Logger getLogger(String name) { |
显然getILoggerFactory才是重点。
1 | public static ILoggerFactory getILoggerFactory() { |
这里通过synchronized + volatile(INITIALIZATION_STATE的类型是static volatile int)保证了在多线程情况下,只有一个线程能够执行初始化操作。
这里再对LoggerFactory的状态展开讲讲:
- UNINITIALIZED:未初始化,也就是一开始的状态
- ONGOING_INITIALIZATION:正在初始化
- SUCCESSFUL_INITIALIZATION:初始化成功
- NOP_FALLBACK_INITIALIZATION:该状态返回的日志工厂为NOP_FALLBACK_FACTORY(类型是NOPLoggerFactory),其创建的日志是NOP_LOGGER,不执行日志操作。
- ONGOING_INITIALIZATION:表示还在初始化中,返回SUBST_FACTORY。该日志工厂创建的日志都是SubstituteLogger类型的,其日志操作实际上交由内部代理执行(在初始化完成前都以记录日志事件的形式保存至eventQueue中;初始化完成后,则执行空操作)。
至于什么时候会被置为这些状态,下文进行了详述。我们接着看performInitialization方法。
1 | private final static void performInitialization() { |
bind方法最主要的目的就是将Slf4j和底层日志实现进行静态绑定。
1 | private final static void bind() { |
到这里,整个过程已经比较清楚了:
- 通过类加载加载资源org/slf4j/impl/StaticLoggerBinder.class,找到所有的日志实现。
- 当底层日志实现多于1个时,进行汇报。
- 执行静态绑定。需要注意的是,在具有多个日志实现时,JVM加载哪个StaticLoggerBinder是依赖于操作系统实现的。并且在JVM成功加载一个StaticLoggerBinder后,不会再加载其他实现(双亲委托模式保证下的类唯一性)。
- 修改状态为SUCCESSFUL_INITIALIZATION。
- 如果是多日志实现,汇报最终使用的日志实现。
这里也展示了之前几个状态的由来:
- 出现NoClassDefFoundError,可能有两种情况:
- 底层无日志实现可绑定,状态变为NOP_FALLBACK_INITIALIZATION。
- NoClassDefFoundError是由于其他类加载导致的,状态变为FAILED_INITIALIZATION。
- 出现NoSuchMethodError,可能有两种情况:
- StaticLoggerBinder无getSingleton方法,则表示绑定失败,状态变为FAILED_INITIALIZATION。
- NoSuchMethodError是由其他情况引起的,则抛出错误。
- 出现其他Exception,状态变为FAILED_INITIALIZATION,并抛出新的非法异常。
- 执行postBindCleanUp方法。
postBindCleanUp方法很重要,我们仔细看一下:
1 | private static void postBindCleanUp() { |
postBindCleanUp方法主要做了这么几件事:
- 修正之前的SubstituteLogger。还记得SubstituteLogger怎么来的么?当一个线程执行初始化时(初始化未结束),另一个线程同时申请创建日志对象,就会返回SubstituteLogger。在初始化结束前,SubstituteLogger都只会把日志操作记录成日志事件,并投放到事件队列中去。那么修正的含义到底是什么呢?
- 将SUBST_FACTORY的postInitialization标记置为true。置为true之后,SUBST_FACTORY后续创建的SubstituteLogger,如果内部没有代理日志对象,那么对于所有的日志操作都执行空。
- 将SUBST_FACTORY现有的所有SubstituteLogger对象,都创建一个真正的日志对象,作为它们的代理。有了代理之后,所有对SubstituteLogger的日志操作都转给相应代理去实现。
- 之前说过SUBST_FACTORY创建的SubstituteLogger在初始化前都会把日志操作以事件存放到事件队列中。此时就是让事件队列中的所有事件回放,然后交给对应的代理日志对象进行真正的日志打印。
- 由于此时初始化已完成,后续使用不到SUBST_FACTORY,所以清空资源。
整个静态绑定的过程到这里也就结束了。
Slf4j占位符实现
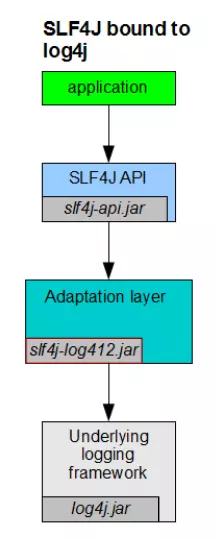
翻了slf4j-api的源码,发现其中的Logger类对于debug、info等方法的调用是直接交给底层Logger实现去处理的。那么slf4j关于占位符的实现到底是在哪里呢?
通过对源码的反复阅读,我发现slf4j-api的确提供了对打印信息中占位符的处理(MessageFormatter类),但是slf4j-api中的Logger的确是直接将方法调用交给下层对象去实现的。其实真正的调用关系如图所示:
1 | final public static FormattingTuple arrayFormat(final String messagePattern, final Object[] argArray, Throwable throwable) { |
log.info("hello " + "world!")使用+号进行拼接,首先当字符串很多的时候,就需要一大串+,很不美观,而使用StringBuilder进行占位符的填充更加优雅。并且在夹杂大部分debug日志(生产环境下日志级别设为INFO)的场景下,性能高于直接拼接。
Logback源码分析
既然说了Slf4j,那顺便把Logback说了吧。以下源码版本为1.1.7,并且代码段之间不一定连续(仅按照调用顺序截取了一部分)。
创建Logger
常见的创建方法如下:
private static Logger log = LoggerFactory.getLogger(xxx.class);然后进入:
1 | public static Logger getLogger(String name) { |
之后的代码位于logback-classic-1.1.7.jar里,主要是.分隔符依次创建父Logger,直到完整名称的Logger创建出来为止。
1 | public final Logger getLogger(final String name) { |
简单概括下创建的过程:
- 查看是否是根Logger,是的话直接返回
- 查看缓存中是否有对应Logger存在,存在则直接返回。
- 按照类全限定名依次创建Logger,例如com.twd.LogTest从根Logger开始的从属关系为ROOT -> com -> com.twd -> com.twd.LogTest,并且父Logger的日志级别会继承给子Logger。
使用Logger打印日志
通过语句log.info("hello world")进行展开。
1 | private void filterAndLog_0_Or3Plus(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params, |
接着开始创建日志事件,然后调用相关Appender。
1 | private void buildLoggingEventAndAppend(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params, |
然后继续往下debug:
1 | // 唤醒与该Logger关联的Appender |
具体的Appender添加LoggerEvent的代码如下:
1 | public int appendLoopOnAppenders(E e) { |
终于到达核心部分:
1 | public void doAppend(E eventObject) { |
继续往下n步:
1 | protected void subAppend(E event) { |
小结
目前描述的仅是Logback的同步日志功能。该功能中,Logback在用户线程中进行打印。当然Logback也支持异步日志打印(有丢失日志的风险),如果有感兴趣的朋友,也可以去了解下。
Logback的逻辑也比较简单:
- 创建Logger
- 若需要创建的Logger已存在Logger池中,那么直接拿出来。
- 若不存在,则创建Logger,并存储在池中。
- 同步打印日志
- 先经过LoggerContext(全局对象)的Turbo Filter的过滤,根据结果判断是否继续。
- 生成LoggerEvent
- 从当前Logger到根Logger自底向上查找,将event添加到所有关联的Appender。
- Appender执行日志打印(此处进行同步),保证每个Appender的日志输出是串行化的。